The first publication arising from PhD student Dave Cayado’s thesis project has just been published in Language, Cognition and Neuroscience. This paper reports a masked morphological priming experiment in Tagalog, investigating the processing of infixes, and comparing them to prefixes and suffixes. Despite their prevalence in the world’s languages, infixes have never before been investigated using the masked priming technique, which is the most widely used tool to investigate the early stages of morphological processing. Consistent with our previous work finding that infixes in Tagalog evoke neural activity consistent with early form based morphological decomposition (Wray et al. 2021), Dave finds that infixed primes facilitate the processing of their stem targets just as robustly as prefixed and suffixed primes do. This important finding means that current models of morphological processing which assume that word edges, or fixed positions, play a critical role in early form based morpheme detection need to be rethought. This research is funded through our SAVANT grant project.
New paper: Dutch–Mandarin learners’ online use of syntactic cues to anticipate mass vs. count interpretations.
Our paper reporting on work investigating Dutch L1, Mandarin L2 speakers ability to use implicitly learned syntactic cues to rapidly generate mass vs. count interpretations (before hearing the critical nominal), has just been published in Second Language Research. This project arises from the PhD thesis of lead author, and QMUL alum, Panpan Yao, now an Assistant Professor at Beijing Language and Culture University. The research was funded by the Advancing the European Multilingual Experience (AThEME) project.
New: Distributed Morphology & Neurolinguistics review chapter on lingbuzz
A chapter Linnaea has written with Laura Gwilliams for the forthcoming Cambridge Handbook of Distributed Morphology is up on lingbuzz. In it, we try to connect the theory of Distributed Morphology with the available neurolinguistics literature (largely focused on the MEG research we and our collaborators have been involved in). Comments very welcome.
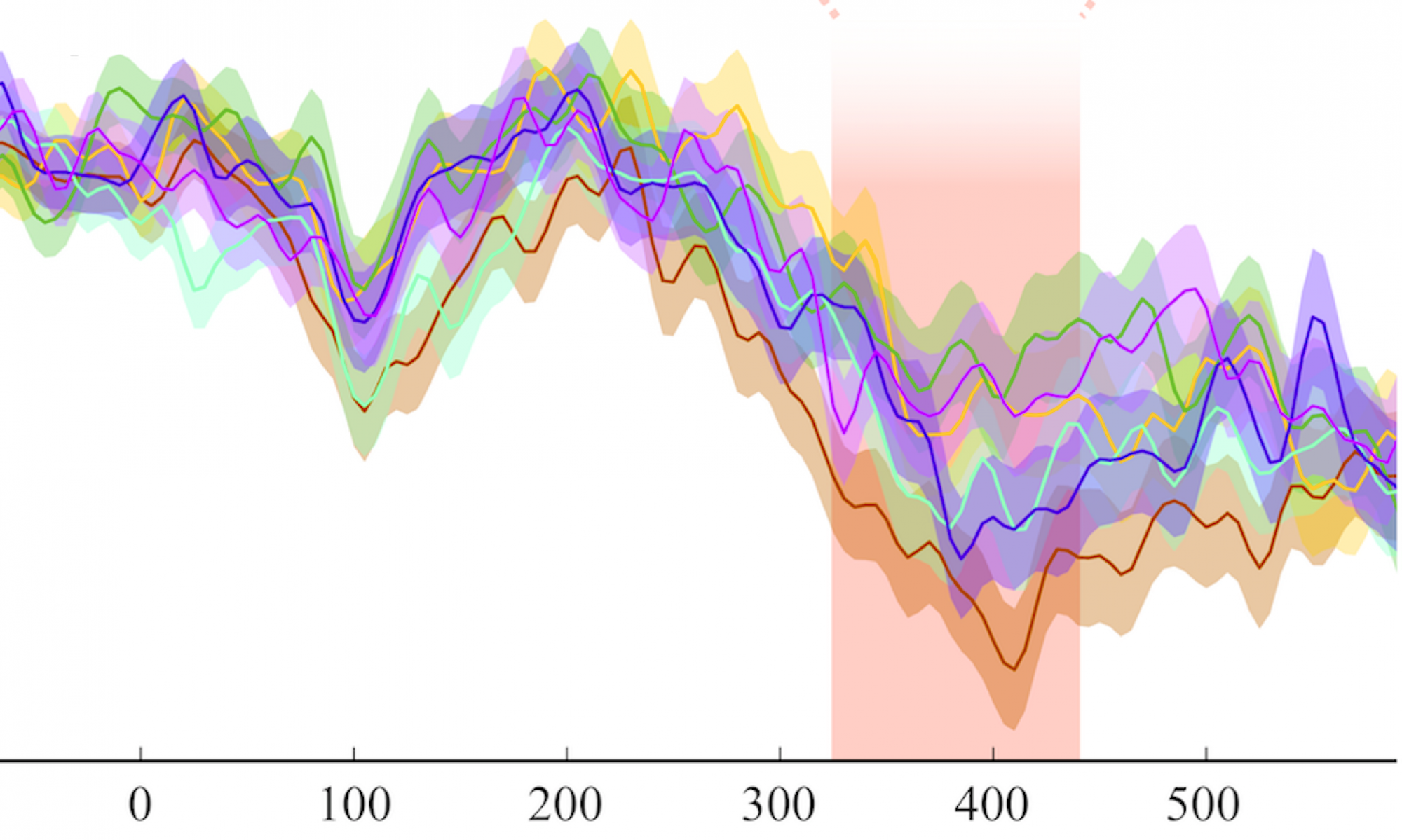
New Paper: Early Form-Based Morphological Decomposition in Tagalog: MEG Evidence from Reduplication, Infixation, and Circumfixation
This groundbreaking study is the first ever to investigate how the morphological processes of Reduplication, Infixation and Circumfixation are parsed using Magnetoencephalography to measure brain responses. The overwhelming majority of research on morphological processing has been restricted to Indo-European languages, in which Reduplication, Infixation and Circumfixation are not present. But these are all perfectly normal and common ways of building complex words in Tagalog and many related Austronesian languages. In this experiment, we have discovered that reduplicated prefixes, infixes, and circumfixes all trigger the same early, form based morphological decomposition mechanisms previously only observed for prefixes and suffixes in languages like English and Greek. MMMRG PhD student, and Tagalog native speaker, Dave Kenneth Cayado is building on these initial results in his PhD research, and we are conducting a follow up study to investigate morphological re-composition as part of our SAVANT project.
SAVANT project awarded funding
We’ve just been awarded funding by the ESRC for our project Systematicity and Variation in Word Structure Processing Across Languages: a Neuro-Typology approach (SAVANT). Research on how the human brain processes language has mostly focused on a very small set of familiar, related European languages like English, Dutch, German, Spanish and French. We know almost nothing about how the brains of speakers of most of the world’s languages respond to even simple linguistic tasks like processing a single word. This project investigates how speakers of a diverse range of languages solve the basic problem of detecting, recognising and interpreting constituent pieces of complex words, by recording their brain activity while they read and judge the wellformedness of familiar and novel words in their language. By employing a very simple paradigm, that can be replicated across all the languages in our sample, we can both better understand the shared neurocognitive bases for the human language capacity, while also uncovering the neurobiological basis for the distribution of different linguistic patterns across the languages of the world. The systematic comparison of the responses evoked by the same manipulations across a range of languages will lead to new discoveries and to the refinement of existing models of how word-internal linguistic structure is parsed.
The project brings together a global team of researchers and labs: Christina Manouilidou in the Department of Comparative and General Linguistics and the Department of Neurology at the Univerza v Ljubljani, Rok Žaucer in the Center for Cognitive Science of Language at Univerza v Novi Gorici, Dustin Alfonso Chacón in the Neuroscience of Language Lab (NeLLab) at NYU Abu Dhabi, Samantha Wray in the Program in Linguistics at Dartmouth College, and Alec Marantz in the Department of Linguistics and NeLLab at NYU.
We’ll be recruiting a team of early career researchers to join our project to help us investigate morphological processing in Tagalog, Bangla, Arabic, Slovenian and Bosnian-Serbo-Croatian in early 2021. The project will run from 2021-2024.
Grant awarded to investigate Cognitive plasticity and language acquisition: The effects of linguistic environment
Professor Heather Goad, and her colleagues at McGill University’s Language Acquisition Research Group (Fred Genesee, Gigi Luk, Stefano Rezzonico, Phaedra Royle, Karsten Steinhauer, Elin Thordardottir & Lydia White), along with a team of collaborators including lab director Linnaea Stockall and other researchers in Canada (Denise Klein, McGill and Johanne Paradis, University of Alberta) and the U.K. (Victoria Joffe, Essex) have been awarded $CAN320,000 for their project Plasticité cognitive et acquisition du langage : l’effet de l’environnement linguistique / Cognitive plasticity and language acquisition: The effects of linguistic environment by the Fonds de recherche du Québec – Société et culture, Programme de soutien aux équipes de recherche. This project will run from 2020-2024.
three new papers about generics
It’s been a productive few weeks for the Generics project team (Linnaea, Dimitra Lazaridou-Chatzigoga and Napoleon Katsos). We’ve just one new paper come out, with two more on the way! We’ve just published our research on how children and adults understand and make new generalisations about ‘striking’ properties that are expressed in the form of a generic statement (eg. glippets love to play with fire). We find that both children and adults are less likely to extend such a property to a novel exemplar, counter to the results of previous experiments, and suggestions in the semantics literature proposing that strikingness licenses generic generalisations for properties with low statistical prevalence (eg. sharks kill people). Read the paper here. This research was funded by our British Academy Small Grant “Learning about the world through generic statements: a cross-linguistic perspective.” (SG-132271).

2019 Lazaridou-Chatzigoga, Dimitra, Katsos, Napoleon, and Stockall, Linnaea. Generalising about striking properties: do glippets love to play with fire? Frontiers in Psychology. doi.org/10.3389/fpsyg.2019.01971
And our work on the processing of generic vs. quantificational generalisations in context will soon be appearing in two publications. In the Journal of Semantics, our paper Contextualising generic and universal generalisations: quantifier domain restriction and the generic overgeneralisation effect. describes a pair of English and Greek experiments demonstrating that the so-called Generic Over-Generalisation (GOG) effect may be largely due to correct, grammatically licensed Quantifier Domain Restriction (QDR) rather than to a processing error. Our paper Experimental evidence on genericity and universal quantification in Greek and English., which will be published in the Proceedings of the 13th International Conference on Greek Linguistics, reports additional experimental work on the Greek quantifiers o kathé and kathé, further supporting the QDR approach.